

1. Introduction
The financial services industry is positioned to benefit substantially from artificial intelligence (AI) applications. The ever-growing interest of regulators, consumers and financial service providers in AI applications has created an influx of research discussing the benefits, threats, and opportunities of AI’s use; however, the trustworthiness, bias and auditability of AI models remain as barriers to implementation (Shawat et al., 2023). Effective research and governance of AI applications are necessary to ensure the continued successful application of AI in the financial services industry. The Trustworthy AI framework (European Commission, 2019) highlights the complex technical and governance requirements relating to the safe use of AI in business, with research in these fields of prime importance in its successful and trustworthy implementation. The FAIR (Findable, Accessible, Interoperable, Reusable) Data Principles aim to support effective, transparent and reproducible research, which is of prime importance in emerging and/or novel research fields, such as AI applications in financial services.
The FAIR Data Principles aid the quest for system-wide research transparency and accessibility; however, this paper highlights a lack of adherence to the FAIR Principles in research on AI applications in financial services. Through an analysis of AI-applied literature published between 2000 and 2023 in finance, taxation and insurance, we find the pervasive issue of opaque and irreproducible research in this space. Findings note that a key reason for this is the ineffectiveness of the FAIR Principles’ applicability to the complex personal and sensitive nature of data employed in this field.
This research paper considers the efficacy of the FAIR Data Principles for the governance of research transparency and accessibility in AI-applied financial services research. The Dutch Tech Centre for the Life Sciences developed FAIR to circumvent similar reproducibility issues regarding research results (Wilkinson et al., 2016) and it has been extended to further research fields, including nanotechnology (Furxhi et al., 2021; Jeliazkova et al., 2021), medicine (Meyer et al., 2021), disaster management (Mazimwe et al., 2021) and research software (Lamprecht et al., 2020). To support the financial services industry in accessing FAIR’s benefits, we propose adapting FAIR by making it more context-specific to the unique industry requirements that exist in this domain. The additional component concerns the introduction of anonymised data (FAAIR) to address the specific operational risks of data collected and employed in financial services. There are significant challenges concerning open data sources in the financial services industry, including sensitive personal information and consumers’ trust in their financial services provider. A lack of research data and results’ availability hinders future research expansion, with “blocked” data sources excluding international development organisations (IDOs) and non-governmental organisations (NGOs) from key decision-making (Rotolo et al., 2022).
Our research issues a call to action in the financial services research domain to develop suitable data principles to protect the integrity of our discipline and shift the power of research knowledge to regulators. This paper extends the FAIR Data Principles to include an Anonymised data guideline, creating the FAAIR Data Principles. The proposed FAAIR Data framework allows financial services research to be transparent and reproducible by researchers and societal bodies.
The importance of AI applications in financial services is noted in the EU with the introduction of the AI Act (European Parliament, 2024), which identifies financial services provision as an area which “deserves special consideration” due to its potential impact on an individual’s standard of living (Smuha, 2025). This aligns with the complex nature of financial services data used for AI applications requiring effective and timely governance, with academic research providing the foundation for many evidence-based policymaking decisions (Head, 2016). However, research funding is often localised within commercial entities, with the research data used and associated results then protected by the organisation.
We draw on Foucault’s power-knowledge theory to explain the problems this research protection creates (Foucault, 2020). Certainly, we highlight the influence financial services organisations can wield over regulators through their ability to control flows of knowledge and information. Foucault’s thinking around the power-knowledge nexus supports the intrinsic link between power and knowledge. Thus, we argue that organisations with access to research funding, data, and research results hold power in the financial services sphere (Adolf & Stehr, 2016). Regulators are hindered in their ability to maintain control of AI’s application in the financial services industry, as they lack access to siloed research outputs on the subject. Additionally, our research supplements capture theory literature by highlighting the role played by knowledge control in policymaking dynamics (King & Hayes, 2018).
This systematic review critically assesses the reviewed articles based on defined criteria (FAIR) for reproducible datasets, highlighting myriad irreproducible studies in the financial services literature set. Research surrounding the use of FAIR Data in medicine has paved the way for reviews that analyse an article’s adherence to the Principles. Meyer et al. (2021) reviewed 152 articles surrounding veterinary epidemiological research published between 2017 and 2020, finding that none of the datasets met the complete requirements set by the FAIR Principles. Similarly, Bahlo and Dahlhaus (2021) reviewed livestock farming datasets in Australia, where low levels of adherence to certain aspects of the FAIR Principles were found.
The literature assessing adherence to the FAIR Principles extends into further inter- and transdisciplinary fields. Mazimwe et al. (2021) is one such paper providing a review of disaster management articles to highlight the need for reusing knowledge discovered in previous disaster management phases. Similar concerns are cited in the following research areas: research software (Katz et al., 2021; Lamprecht et al., 2020), bioscience (Smith & Sandbrink, 2022; Suver et al., 2020), computational science (Wolf et al., 2021), nanotechnology (Furxhi et al., 2021), and environmental science (Harjes et al., 2020). To rectify the reproducibility issue in financial services research, an adapted FAIR Guideline to account for anonymised personal sensitive data for research purposes is proposed to aid the expanding cross-disciplinary network of AI-based financial services research. Additionally, a collation of relevant academic and professional literature on AI applications in financial services will be helpful for regulators’, financial services practitioners’, IDOs’, and NGOs’ informed decision-making surrounding ethical considerations of AI regulation in response to social injustices, namely financial exclusion.
This paper presents the first systematic review and critical analysis of AI-applied finance, taxation and insurance articles’ adherence to the FAIR Principles. This research is significant as it highlights the current state of AI applications in the financial services industry and the lack of transparency and reproducibility in the literature. This lack of transparency acts as a roadblock to the further application and development of AI while ignoring the research field’s importance in civil society’s decision-making. A strong regulatory regime is necessary to aid the further deployment of AI’s use in financial services. The development of an adapted FAAIR framework will promote evidence-based policymaking by increasing research data and results sharing between industry, academia, and policymakers (Mulgan, 2005).
1.1. Related Literature
This paper has four main components: the FAIR Data Principles, AI applications in finance, AI applications in taxation, and AI applications in insurance. This section of the paper analyses the existing literature related to each of these components, thus highlighting the gap in the literature surrounding the absence of FAIR Data evaluation within AI-based financial services articles and the ensuing issues for policymakers. Transparency in AI applications is twofold – there are “outward” forms of transparency, which are most often discussed in the literature, and “functional” transparency, which is the subject of discussion in this paper (Walmsley, 2021). Functional transparency includes, yet is not limited to, the datasets used in both the training of AI models and the understandability of the AI models’ results, having contextualised such results with the knowledge of the inner workings of the models. The use of quality datasets for applied AI research is paramount, as the AI models rely heavily on their data inputs for training and testing purposes. Without sound data management and data quality checks in applied AI financial services research, the literature set may suffer the consequences of biased or inaccurate research results (Aldoseri et al., 2023). Additionally, for successful replication and validation of applied AI financial services research, the completeness, integrity, relevance and timeliness of analysed datasets should be verifiable by other researchers (Batista & Monard, 2018; H. Chen et al., 2012; Halevy et al., 2016; Karkouch et al., 2016).
Open data refers to the provision of research data publicly, which plays a crucial role in transparency ambitions for governments and research bodies (Splitter et al., 2023). The decision to decide what data eventually becomes available is often left to data providers. However, a call for open science necessitates open data repositories. Open science is the process of involving the public in science (Splitter et al., 2023). This facilitates inclusive engagement by the public, in turn empowering citizens in evidence-based decision-making (Janssen et al., 2012; Yu & Robinson, 2011; Zhu et al., 2019). Underpinning open science are three foundational pillars: accessibility, transparency, and inclusivity (Beck et al., 2020; Maedche et al., 2024). The FAIR Principles promote open data as a precursor to open science by focusing on data sharing, ensuring access and the reusability capacity of research data (Jati et al., 2022).
FAIR Data Principles
Appropriate data management is essential for research validation throughout each stage of a research project and is a step researchers understand they ought to engage in but rarely want to (Kowolenko & Vouk, 2018). Reasons abound for the necessity of reproducible research findings, including the opportunity to validate research results and encourage the reusability of data and research methodologies to further contribute to a given research space (Peng & Hicks, 2021). Issues with data management arise as metadata capturing is not implemented in everyday scientific research practices. This is partly owing to a lack of data management training and the general understanding that data management occurs at the end of a project following data publication (Furxhi et al., 2021; Papadiamantis et al., 2020).
The establishment of the FAIR Data Principles in 2014 (published in 2016[1]) heralded the beginning of inter- and cross-disciplinary research transparency by establishing a minimal set of rules for research data stewardship in the life sciences domain (Boeckhout et al., 2018). Structured on four main pillars – Findable, Accessible, Interoperable, and Reusable – these Principles present an inter-sectional attempt to ameliorate the access, use and reuse of digital resources by humans and machines (Wilkinson et al., 2016). These Principles intend to give a minimal set of community-agreed guidelines to follow, such that humans and machines can carry out the four facets (FAIR) on the used dataset relatively easily (Dunning et al., 2017). Wise et al. (2019) emphasise the importance of research data which complies with the FAIR guidelines: Findable, Accessible, Interoperable and Reusable data enable digital transformation and societal progress (Romanos et al., 2019). A significant note on the Principles is that they precede the implementation choices of (AI) models and, therefore, only provide a set of recommendations for data researchers and publishers to assist in evaluating the data being used (Wilkinson et al., 2016). Although a step in the right direction for research transparency, there is a lack of actions in implementing FAIR Data practices in many research areas, with the risk of incompatible implementations likely to cause future issues for researchers (Jacobsen et al., 2020).
Introducing more prevalent use of FAIR Data has been seen most commonly amid medical literature in the hopes of solving the issue of data that are not interpretable by those who are not an expert on the dataset (Kalendralis et al., 2021). Wise et al. (2019) point towards the current lack of technology and standards in the biopharmaceutical industry to support the implementation of the FAIR Principles. The paper suggests that the industry must move from an inward focus to a more outward-looking one that fully supports data-sharing to progress quickly. Similarly, Alharbi et al. (2021) highlight the need to build a technical infrastructure within the biopharmaceutical industry that supports large-scale FAIR implementation. In contrast, Holub et al. (2018) proposed an extended version of the FAIR Principles for use within medical research, suggesting that the current guidelines are not practical enough for that industry.
Both governments and researchers are exploring alternative methods of data governance to improve research transfer and data sharing in industries particularly impacted by AI, including finance, insurance, and medicine (He et al., 2022). The European Union has provided substantial investment in data-sharing spaces, aiming to develop the FAIR Principles into standardised criteria and indicating which facets of the Principles can become official research policy (Groth & Dumontier, 2020). Furxhi et al. (2021) provide important work on the “FAIRification” process of research datasets and methods in nanotechnology, while Rashid et al. (2020) provide a practical approach for proper annotation of standardised and machine-readable datasets. Gajbe et al. (2021) review several data management plans to assist researchers in choosing appropriate structures to aid their data management process. There appears to be a shift from viewing datasets as a byproduct of a research project to a value-enhancing asset whose value increases the more it is used (Leonelli, 2016; Wilkinson et al., 2016). This shift necessitates further classification of “FAIRified” datasets in AI research and identifying methods to promote the implementation of the FAIR Principles across a wide range of research disciplines.
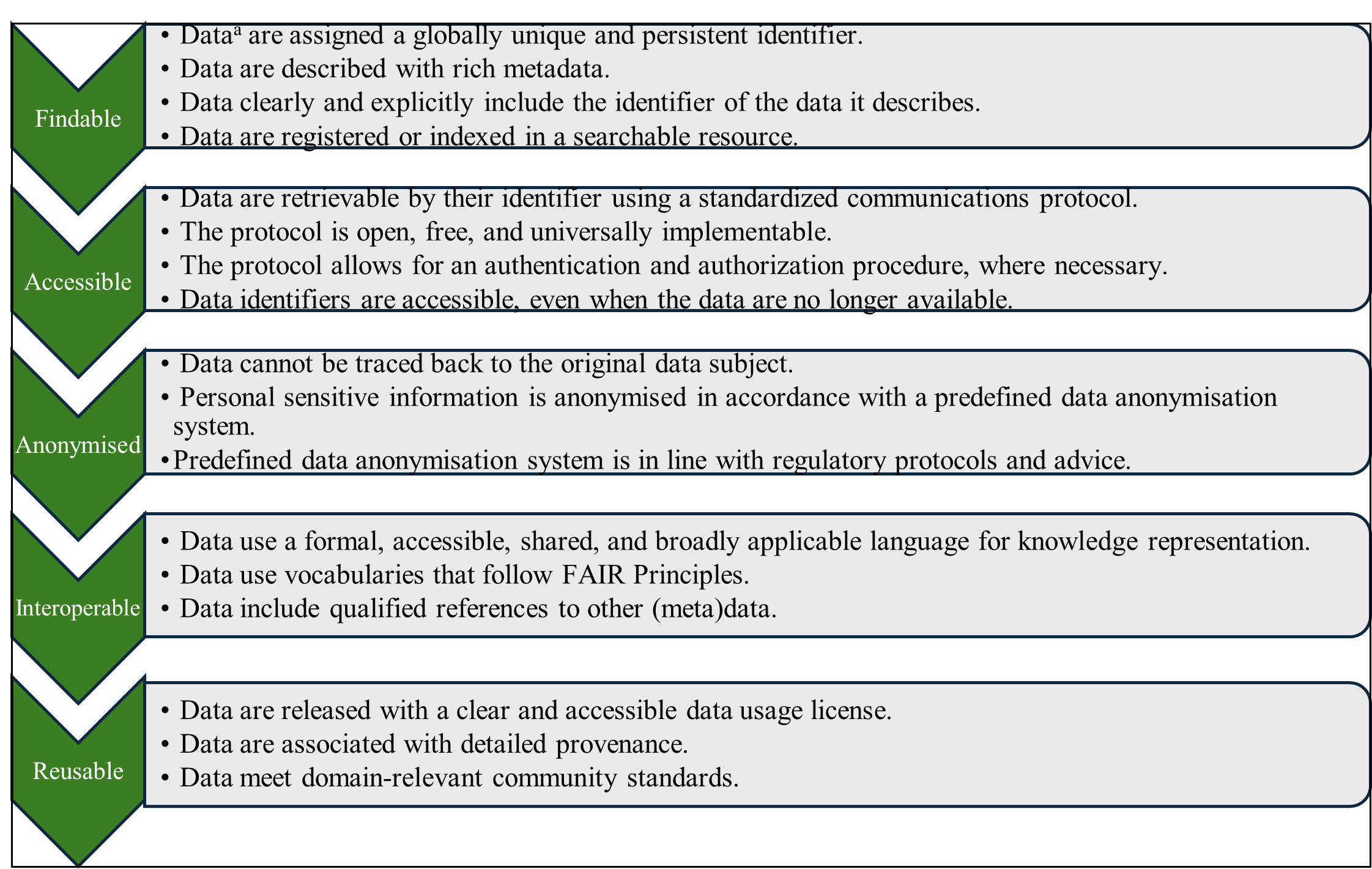
Defining the four facets of the FAIR Data Principles concisely using plain language is quite difficult. It is important to note that data are information that can be operated on or analysed, whereas metadata describes the relevant information about the data. The first publication of the FAIR Principles by Wilkinson et al. (2016) provides complex, official explanations of each of the four pillars, breaking them down further into a number of actionable guidelines (Figure 1).

The first pillar, “Findable”, is the most essential step in the process, as data openness and findability enhance their value to the academic community and decision-makers. Vesteghem et al. (2020) define Findable data as that which can be found online through indexing in search engines. While this definition is concise and straightforward, this systematic review analysis will refer to Findable data as that which are described, identified, and indexed in a searchable resource clearly and unequivocally (adaptation of Boeckhout et al. (2018)’s definition).
The second pillar, “Accessible”, relates to the need to make the used databases more accessible to the public. Vesteghem et al. (2020) claim that the data must be retrievable through a standard procedure or an approval process. Conversely, Wilkinson et al. (2016) note that metadata must always remain accessible. This issue regarding the lack of persistent metadata (when the data are inaccessible) is an essential but overlooked part of the FAIR Principles. To construct this more plainly, Wise et al. (2019) break it down into three major components: access protocol, access authorisation, and metadata longevity. So, the data must have a distinguished access procedure that should allow for authentication, if necessary, with metadata that always remains accessible.
The third pillar, “Interoperable”, is premised on increasing data integration at every level to allow the data to be used and understood by computer systems. Boeckhout et al. (2018) provide a simple but concise version of the definition where it is claimed that the data and metadata must be conceptualised, expressed and structured using common published standards. However, one concept that is not explicitly stated in these definitions yet assumed to be inherently present is the importance of the data being machine-accessible (Tanhua et al., 2019). This machine accessibility is essential for a data publisher, as datasets can slip through automated searches if this accessibility is not present.
The final pillar, “Reusable”, aims to optimise the ability of the data to be reused by others. If data are to be deemed Reusable, then they must already be deemed Findable, Accessible and Interoperable. We combine definitions given by Boeckhout et al. (2018) and Rodríguez-Iglesias et al. (2016) and state that Reusable data should have their characteristics described in detail according to domain-relevant community standards and with a clearly defined mechanism for accessing provenance and license information.
AI Applications in Finance
Ahmadi (2024) provides an all-encompassing overview of how AI is changing the current financial landscape, citing fraud detection and compliance, banking chatbots, and algorithmic trading as the most successful implementations of AI in financial services (Mahalakshmi et al., 2022). Similarly, Tekaya et al. (2020) offer an overview of AI applications in other areas of finance, namely credit risk management, the banking sector, and insurance. Several other articles provide more precise research on a specific use of AI, such as Choi and Lee (2018)’s paper, which reviewed the newest financial fraud-detection technique to assess its viability. Similarly, Gómez Martínez et al. (2019)’s paper describes an algorithmic trading system whose decisions are based solely on investors’ moods through the use of big data. Singh and Jain (2018) focus on using AI engines within financial institutions, describing how certain banks use an AI engine that mines data, creating consumer profiles that can then be matched to wealth management products they would most likely desire. Similarly, Alexandra and Sinaga (2021) conducted data mining on a dataset of client subscriptions in Portuguese banks to predict whether the banks’ clients would subscribe to a term deposit. The research found that the Random Forest model (RF) was the most effective classification method, and the K-medoids model was the most effective clustering method in terms of prediction accuracy.
The use of AI in the financial services industry has already proven successful (Fisher et al., 2016; Senave et al., 2023; Xing et al., 2018), with the current wave of AI growth (especially relating to generative AI and large-language models (LLMs)) impacting the industry even further. AI models hold the key to greater financial intelligence, which presents the financial services industry with the opportunity to reduce inefficiencies and costs (Douglas, 2024; Fares et al., 2023). The increased use of AI presents many commercial benefits. However, there are risks associated with the opaqueness of such AI models (Agu et al., 2024). Many of the aforementioned AI models lack transparency, which explains how they reached their conclusions. With public trust in banks and financial institutions remaining low since the global financial crisis, deploying an AI system that accepts or denies loan applications without an accessible reason could only further dissipate this trust (Jadhav & Khang, 2025).
AI Applications in Taxation
The use of AI in taxation is a complicated process, as there is a balancing act present between the rationalisation and democratisation needed to implement a successful AI system and striving for equality using tax policies and legislation while achieving maximum possible tax compliance (Mökander & Schroeder, 2024). Z. Huang (2018) contributes to the overall literature with an overview of current AI developments that are remoulding the taxation sector, discussing tools that are primarily easing the issue of complex data processing within the sector for pertinent issues, such as tax evasion. Adamov (2019) further adds to this discussion, focusing on the importance of AI in tax fraud detection, with AI research and models signalling a unique opportunity to enhance tax compliance.
Raikov (2021) presents a potential AI system based on neural networks and cognitive modelling that predicts tax evasion events, research that enhances tax practitioners’ and regulators’ capacity to circumvent such occurrences. Interestingly, the author also notes the relationships created in the digital environment (digital transactions, e-commerce and cryptocurrencies), which make such evasion events difficult to regulate (Rahman et al., 2024). The paper showcases how deep learning applications can be leveraged to predict evasion using complex decision-making systems involving text analysis (Raikov, 2021). However, the authors do not consider the issues of trust, transparency, and fairness due to the lack of interpretability or explainability of these deep neural network models, issues to which regulators must pay close attention. Predictive models such as these have gained popularity in the literature, with Nembe et al. (2024) further highlighting the benefits of AI for tax-evasion mitigation and tax non-compliance identification. Additionally, Baghdasaryan et al. (2022) developed a tax-fraud classification model using numerous machine learning (ML) tools in a similar fashion to Pérez López et al. (2019), who used a neural networks-based model for tax-fraud detection. Baghdasaryan et al. (2022) developed a useful ML tool for tax-fraud prediction, even with missing significant data features, such as historical audits or previous instances of fraud. Alongside this, Pérez López et al. (2019) present a classification analysis of an individual’s propensity to commit income tax fraud, applying the Multilayer Perceptron network analysis. The model was found to be ~85% effective at classifying potentially fraudulent taxpayers, therefore offering governments a method of bolstering their tax-compliance capabilities.
Looking toward policies, Zheng et al. (2022) comment on the form AI-driven taxation policies would take in comparison to the current baseline policies, noting that the policies utilising reinforcement learning are significantly different and more efficient than the baseline policies in reducing inequality. Mökander and Schroeder (2024) also highlight the social and ethical tensions in using AI in tax policy automation and optimisation. As AI implementation requires rationalisation and democratisation of the tax policymaking process, ethical policymaking and decision-making autonomy may be hindered (Mökander & Schroeder, 2024).
All of these AI methods require vast amounts of sophisticated and personal data to function effectively. However, taxpayer data are highly sensitive and must be protected from unauthorised access (Ezeife, 2021). Aziz and Dowling (2019) comment on the problem of sharing personal financial data, which poses challenges to those publishing their research to propel the use of AI within finance or taxation. This paper highlights how this problem is much more prevalent within the taxation literature, where papers often fail to adhere to the FAIR Principles simply because the data they use cannot be disclosed or even described. (Tax) accountants are tasked with deploying the ethical use of AI in financial services, with building their knowledge of ethical AI practices seen as a proactive approach to AI risk management (Schweitzer, 2024). Aziz and Dowling (2019) particularly highlight the role of the General Data Protection Regulation (GDPR) (EU, 2016) in this risk-management process, which enforces regulations regarding the use of personal data. A potential solution to this problem is presented later in the paper in the form of data anonymisation.
AI Applications in Insurance
Many articles highlight the importance and advantages of AI applications in the insurance industry, with a further influx of AI applications in the industry expected in the coming years (Owens et al., 2022; Paruchuri, 2020; Riikkinen et al., 2018; Umamaheswari & Janakiraman, 2014). Fraud detection (Sithic & Balasubramanian, 2013; Verma et al., 2017) and claims reserving (Baudry & Robert, 2019; Blier-Wong et al., 2021; Lopez & Milhaud, 2021; Wüthrich, 2018) are two areas which offer the most significant potential for AI implementation. AI provides long-term profitability growth potential to insurance companies primarily through enhanced risk assessment (Grize et al., 2020). Sarkar (2020) argues that the insurance industry holds the potential for algorithmic capabilities to enhance each stage of the insurance value chain (IVC). By highlighting AI’s offerings at each stage of the IVC, the research prompted further studies from Walsh and Taylor (2020) and Eling et al. (2021) to determine precise AI opportunities available to the insurance industry. Walsh and Taylor (2020) highlight AI models’ ability to mimic or augment human capabilities with Natural Language Processing (NLP), Internet of Things (IoT), and computer vision. Eling et al. (2021) analyse AI’s impact at each stage along the IVC and specifically highlight AI’s potential to enhance risk assessment (loss prediction and prevention) and revenue streams for insurance practitioners.
Applied research in the AI for insurance literature set highlights the specific instances where AI can be used along the IVC. Ensemble models are most popular in insurance use cases, with neural networks and clustering models also proving popular (Owens et al., 2022). Fang et al. (2016) used big data to develop a new profitability method for insurers using historical customer data, where they found that the RF model outperformed other forecasting methods (linear regression and Support Vector Machine (SVM)). Shapiro (2007) documents the extent to which fuzzy logic (FL) has been applied to insurance practices, which prompted Baser and Apaydin (2010)’s research on claims reserving using hybrid fuzzy least squares regression and Khuong and Tuan (2016)’s creation of a neuro-fuzzy inference system for insurance forecasting. Decision trees (DT) are often used in insurance claims prediction (Quan & Valdez, 2018), with further research citing the low predictive power of DTs. Therefore, Henckaerts et al. (2021) boosted DTs’ intrinsic interpretability to create a robust insurance pricing model. As AI is impacting each stage of the IVC, an analysis of its specific use cases along the IVC will help regulators assess and, ultimately, govern AI-applied insurance industry operations. Human bias and dataset bias, leading to potentially discriminatory insurance practices, are pertinent concerns for insurance policymakers.
The bias inherent to black-box AI systems threatens trust within the insurance industry, with this bias primarily driven by either humans’ input or algorithmic bias (H. Koster, 2020; Ntoutsi et al., 2020). There is potential for these models’ impediments to compound and extenuate bias in their decision-making processes with unfair outcomes possible within the insurance industry (Confalonieri et al., 2021; O. Koster et al., 2021). Bias in AI models could potentially lead to discriminatory behaviour in the AI system caused by the model’s tendency to use sensitive information resulting in unfair decisions (Barocas & Selbst, 2016). There is substantial research conducted on the determination of responsible AI, with O. Koster et al. (2021) providing a framework to create a responsible AI system, and Arrieta et al. (2020) outlining degrees of fairness to be implemented in an AI system to reduce discriminatory issues. Transparency and accountability of AI research in the insurance industry are therefore of paramount importance to ensure a successful AI-infused insurance industry for many years to come (EIOPA, 2021). Additionally, taxation and the provision of insurance are agents of governmentality and, ultimately, state power (Pellandini-Simányi, 2020). Therefore, refining an open and accessible research set on AI’s impact on these industries is necessary.
2. Methodology
The selection of suitable databases as the sources for the systematic search was based on Gusenbauer and Haddaway (2020)’s paper, which reviewed over 20 databases and tested their ability to perform quality systematic reviews while also identifying which databases are best suited to each research area. The systematic search was conducted on EBSCOhost (EconLit and Business Source Complete), ACM Digital Library, Scopus, Web of Science, and IEEE Xplore. These databases were selected due to their content primarily focusing on economics and business, along with a computer science-based database to access research papers with AI applications. This group of academic search systems are well-suited to systematic reviews because they meet all necessary performance requirements and can be used as either principal or supplementary search systems (Gusenbauer & Haddaway, 2020).
To form a consistent, systematic search, this paper uses a combination of keywords to grasp the full breadth of relevant papers (Table 1). The breakdown of “taxation” terms is influenced by Redondo et al. (2018). Similarly, interchangeable “finance” terms are adapted from Akomea-Frimpong et al. (2022)’s and X. Xu et al. (2018)’s systematic reviews. Interchangeable search terms for “insurance” are derived from Owens et al. (2022) on the proliferation of Explainable Artificial Intelligence (XAI) in insurance. Eling et al. (2021) provide a table of terms that can be used interchangeably with three key AI terms (Artificial Intelligence, Smart Devices and Artificial Neural Network). The broad set of search terms encapsulates a comprehensive list of articles that demonstrate the breadth of AI applications within financial services.
The search criteria for each of the aforementioned databases are as follows[2]:
-
Time period: Articles[3] published between 1st January 2000–31st December 2023 are included.
-
Relevancy: The presence of keywords (Table 1) in the abstract is necessary for the article’s inclusion. Additionally, the article must be relevant to assessing AI applications in financial services (encompassing finance, taxation and insurance for the current study); and only articles which utilise a dataset for their study are included (i.e., no systematic reviews or discussion articles).
-
Singularity: Duplicate articles found across the various databases are excluded.
-
Accessibility: Only peer-reviewed articles that are accessible through the aforementioned databases and are accessible in full text are included (i.e., extended abstracts are not included).
-
Language: Only articles published in English are included.
The initial screening process involved the analysis of 1,672 articles (following duplicate removal) based on their title, abstract and relevancy to the analysis. After filtering the literature using the above criteria, 102 articles were included for FAIR assessment. A backward search involving the evaluation of the 102 relevant articles’ bibliographies for additional articles relevant to the topic was conducted, identifying a further 24 relevant articles. This entailed searching through the citations of the remaining literature, ensuring the review would gather up any related articles that may have been missed in the initial search process. A final sample of 126 articles (including backward search results) was established. The PRISMA flow diagram (Figure 2) depicts the systematic review process, displaying the number of articles excluded at each review stage.

2.1. Literature Extraction Process
The evaluation of the full-text articles within the three literature sets followed a two-step process:
-
Recognition: The applied AI method was recognised, along with the employed dataset.
-
FAIR Data Analysis: Each article was assessed per the FAIR Data Principles.
The authors conducted a manual assessment of the articles to determine their adherence to the FAIR Data Principles. Using the FAIR Principles framework (Figure 1), the authors assessed each of the FAIR steps according to their specific features (i.e., Findable – Is the unique identification number visible to the authors? Are the data adequately described with rich metadata? Are the data indexed in a searchable resource/database?). These features are adapted from Wilkinson et al. (2016)’s official FAIR framework.
The listed AI methods are adapted from Payrovnaziri et al. (2020) and Owens et al. (2022) systematic review papers. An outline of the process is described in Table 2 above.
2.2. Research Limitations
Industry reports are excluded to ensure the validity and reproducibility of the systematic review. Access to complete methodological processes is pertinent to the systematic review, as the used datasets and their corresponding description are often observed in this section. Industry reports often omit this section in their publication.
3. Results – Reproducibility Evaluation
Like many other research fields, AI and ML face a reproducibility crisis (Gibney, 2022). We similarly observed a lack of reproducible studies during this systematic review of articles. A summary of the FAIR Data Principles is provided in Figure 1, which informs the reproducibility criteria used in the current systematic review. Following the review of 126 articles, 35 articles (29%) were identified as fully satisfying the criteria of open and reproducible datasets, with a further 26 articles (21%) partially satisfying the criteria. Table 3 acknowledges those articles which satisfy the FAIR Data Principles. This low number of reproducible studies highlights the lack of adherence to open data and open science objectives amongst the financial services research community, which could impede research, development, and innovation in the applied AI domain.
The adherence to the FAIR Principles in the financial services research domain highlights a stark need for further efforts in reproducibility-enhancing practices by researchers. Finance articles have the highest level of FAIR Principles adherence (67%), primarily due to the use of synthetic datasets for analysis. Insurance (44%) and tax (5%) typically do not refer to the datasets used for analysis, or the datasets analysed present personal information such that they cannot be shared publicly with the article’s publication. Several articles that did not provide clear direction or insights on the dataset used were concerned with prediction tasks. Such datasets were either anonymised or did not highlight the reasoning for the lack of dataset identification. We note that several of the reviewed studies utilised a simulated dataset, as real-life datasets can sometimes be too short term to test the validity of newly proposed models[4].
The analysis further finds that data repositories (including Kaggle and UCI Machine Learning Repository) show strong adherence to the FAIR Data Principles, compared with stand-alone published datasets, e.g., Lending Club Dataset and PPD Credit Dataset. These repositories offer a structured place for researchers to deposit their datasets, allowing easier and safer access and downloading. Normore and Tebo (2011) point towards the importance of long-term planning for data preservation and storage, along with standard data methods and policies. Data repositories that are frequently used in articles that fully satisfy the FAIR Principles offer long-term data storage and preservation, with the ability to update the dataset if required. Repositories such as Kaggle display Creative Commons licensing information, offering clear usage rights to potential data users. This is one of the main benefits of these repositories, as it clarifies any researcher’s ambiguity about reusing a dataset. A reoccurring theme in datasets that were not published on respected repositories such as Kaggle or the UCI Machine Learning Repository was that the dataset failed under just a single facet of the FAIR Principles. Some of the reoccurring themes include but are not exclusive to (1) inadequate metadata, (2) lack of persistent identifiers, (3) accessibility issues, and (4) reusability issues.
3.1. Inadequate Metadata
A common inadequacy of several datasets was the lack of rich and extensive metadata. Metadata is data or descriptive information about the dataset, including its context, quality, and characteristics (Guptill, 1999). Rich metadata ensures that the data can be used for other purposes along with its intended initial use. However, datasets that lacked sufficient metadata were not only exclusive to datasets outside of respected repositories. One such dataset is the UCI Machine Learning Repository – Australian Credit Dataset, which appears numerous times across the literature. The data concerns Australian credit card applicants and is not dissimilar to the UCI Machine Learning German Credit Dataset (Hoffman, 1994). However, the Australian Credit Dataset lacks the rich metadata needed for the data to be considered flexible and useable in different contexts. The issue lies in data confidentiality, which forces the data providers to assign meaningless values to the attributes. The UCI Machine Learning – Japanese Credit Screening Dataset (Sano, 1992) provides even less metadata, lacking even basic details such as the number of attributes in the data or if there are missing value points – essential pieces of information. Data confidentiality is not mentioned as an issue in this instance, meaning a dataset such as this can smoothly transition into a FAIR dataset with increased metadata input.
3.2. Lack of Persistent Identifiers
Several datasets were not shared due to confidentiality reasons. However, the data, along with their corresponding metadata, should still be assigned a persistent identifier so that they are easily Findable. Didimo et al. (2020) apply ML algorithms in a tax-risk assessment manner using taxpayer data provided by the Italian Revenue Agency. These data were not shared due to confidentiality reasons, nor were they assigned a persistent identifier, making the informative research irreproducible. Similarly, L.-H. Li et al. (2017) use credit records of small loan applications provided privately by a Brazilian commercial bank. Again, the dataset is not contained within a persistent identifier.
3.3. Accessibility Issues
The issue of open and closed datasets is an important topic of debate, and the FAIR Principles offer flexibility around the issue. The Principles allow for a dataset to be private once its metadata is publicly available and accessible. Often, datasets did not provide open-source metadata, meaning they did not fully satisfy the accessibility requirements. One such instance is the dataset analysed by Gu et al. (2020a). The article provides sufficient metadata to distinguish the dataset from others, but its persistent identifier exists on the Wharton Research Data Services website. An institutional login is required to see both the data and metadata, meaning the dataset is not fully accessible. This is a persistent issue across datasets that exist on the Wharton Research Data Services website. Siloed data such as the abovementioned datasets create an access-to-knowledge imbalance amongst researchers and commercial institutions, whereby only researchers with the means to pay for datasets behind paywalls can further contribute to the literature set using those data. Additionally, research published using inaccessible datasets is often irreproducible, thereby hindering the validity of the research outputs. It is those researchers, research groups or commercial bodies who have the means to either pay to access datasets or collect primary data from individuals themselves who hold the power to further the literature set via research publications (Foucault, 2020).
In a similar fashion, hyperlinks to datasets can become obsolete over time. In this scenario, there should still be accessible metadata at the very least to describe these now obsolete data, which was not the case in most instances. For example, Liu et al. (2021) are open with their data, providing links to two datasets used in the research. However, the link to one of these datasets has since become obsolete, with no persistent metadata present, meaning a failure under the second Accessibility principle.
3.4. Reusability Issues
An issue that is briefly discussed above is the lack of clear usage rights attached to a dataset. Often, datasets that are not published on academic data repositories do not clearly state their usage rights, meaning a researcher hoping to reuse the data may simply avoid using them to prevent copyright infringement. An example of one such dataset is that which is used in Bianchi et al. (2021)’s paper focused on the predictability of bond returns. This dataset (Cynthia Wu, 2021) fully satisfies all aspects of the FAIR Principles but fails to provide any obvious licensing information that would be clearly acknowledged in any automated searches. Providing a simple usage license to these data would transform this unique dataset into a distinctly valuable and reusable asset.
4. Discussion
4.1. Research Accessibility Crisis and Regulatory Challenges
Research progress hinges on the sharing of information through two generic processes: exchange and collaboration (Nahapiet & Ghoshal, 1998). As outlined in the previous results section, there is a significant lack of reproducible datasets present in AI and financial services research, with 65 articles analysed in this paper not adhering to the FAIR Principles in any instance. Highlighted in Section 3 are the most commonly reoccurring reasons for research datasets not being published: 1) inadequate metadata, 2) lack of persistent identifiers, 3) accessibility issues and 4) reusability issues. Firstly, the lack of emphasis on AI studies’ reproducibility hinders both significant regulatory progress and research enhancement within the industry. If researchers used publicly available datasets which satisfy the outlined FAIR Data Principles criteria, their studies’ validity could be ascertained. In addition to the validation of research findings, future studies could expand on research methodologies in tandem with advances in technology adoption. The lack of available datasets significantly restricts the furthering of regulatory, academic, and professional knowledge on the ubiquity of AI applications in a wide range of financial services tasks, limiting researchers’ scope for research development. The exchange and collaboration of sensitive datasets between commercial and academic entities for research purposes may hamper cross-industry innovation for AI use in financial services (Nahapiet & Ghoshal, 1998). Additionally, if the academic community cannot gain access to relevant commercial datasets due to their sensitive nature, the conversation between policymakers and academia will falter, leading to ill-informed policy decisions on AI applications in financial services (Head, 2016).
We cite the issue of lacking dataset availability in financial services research as a reproducibility crisis, which contrasts with Jensen et al. (2023)’s findings, which negates a “replication crisis” in financial economics. Their findings conclude that much of the literature sample can be replicated[5], which the authors initially expected to be similar to the findings of the current paper. However, this contrast in reproducibility potential in three closely related fields of finance research (vs. financial economics research) shows that reproducibility is possible in financial services research datasets, albeit with additional obstacles in the case of the financial services industry, such as sensitive and confidential personal data on consumers, as outlined above. Without harnessing the potential for research reproducibility through accessible datasets, financial services research is at risk of significantly lagging behind its financial economics colleagues. Without transparent research practices and accessible data, the advancement of AI-applied financial services research could additionally fall behind commercial financial institutions’ practices, rendering researchers’ work out of date and irrelevant once published.
Although a call for publicly available datasets in various research communities is welcomed (Christensen & Miguel, 2018; Vetter et al., 2016), the financial services industry faces additional challenges regarding dataset access. Data collected by insurers and banks, in particular, are usually of a highly sensitive nature, with insurance and credit proposal forms asking for specific information about proposed insureds in many cases. Researchers have attempted to overcome this issue by utilising synthetic datasets in their analysis due to heavily restricted access to financial services companies’ datasets. Such issues are only heightened by recent and ongoing regulations in the industry that protect proposed insureds’ and credit customers’ right to privacy and the safe-keeping of sensitive data shared with insurance companies and banks, such as GDPR regulations (EU, 2016). Therefore, only financial services entities (insurance companies, banks, commercial finance firms) regularly hold a sufficient repository of data on multitudes of data subjects. In some instances, however, academic researchers can access anonymised datasets when needed for analysis. This practice is facilitated by commercial entities charging a fee in exchange for anonymised datasets. This “paywall” maintains the integrity of datasets’ use to some degree by ensuring that proper anonymisation of datasets is completed, as commercial entities are paid for this service by researchers via the dataset-access fee.
Although a practical and regulatory sound process in relation to data privacy, the practice of holding financial services subjects’ anonymised data behind paywalls is damaging to regulatory and academic research progress (Hagger, 2022). As outlined in the above review of financial services literature, research reproducibility levels are low as often researchers cannot share datasets they have used in their analysis, even if they have paid a fee for such data. In essence, researchers can pay a fee to utilise datasets in their research. However, this fee does not make them an “owner” of such anonymised datasets. Therefore, scholarly research results published in financial services domains, although peer-reviewed and published in academic journals, often lack validation and research reproduction capabilities. The continuation of this practice in tandem with the FAIR Principles’ popularity growth seems counterintuitive. However, in some research fields, such as financial services, the protection of data subjects’ privacy remains a priority. It is for this reason that an adapted FAAIR framework, including the process of anonymisation, is necessary for the future of financial services research. Regulatory advancements and the associated risk management of AI applications in financial services will benefit from extensive and verified research. These research results will be based upon analyses of relevant datasets (with or without sensitive information included), not just those datasets which the researchers can access while operating within the bounds of stringent anonymisation regulations.
The anonymisation of datasets is possible, with such actions already undertaken in genomic research (Corpas et al., 2018) and government-level policy decisions (Ritchie, 2014). The creation of an open-access data anonymisation toolkit for financial services research would benefit the research community by enabling reproducibility and validation of results, which will, in turn, allow for a successful and thorough implementation of AI models in financial services practices.
Finally, from a broader societal perspective, policymakers, IDOs, and NGOs routinely struggle to gain sufficient insights to inform evidence-based decision-making for social progress. While government bodies and regulators increasingly rely on external organisations’ research data to inform their policymaking, there exists a distinct lack of open and accessible research data in the financial services industry (Mehrban et al., 2020). Financial services regulations employ a subsidiarity approach to regulation, whereby industry players can govern themselves internally once complying with specific industry-wide regulations. By allowing commercial entities to maintain control of their internal operations, policymakers lack access to key research data created and protected by commercial entities (McKinlay et al., 2012). Siloed and inaccessible data are also a key obstacle to IDOs’ and NGOs’ ability to partake in decision-making on behalf of their stakeholders. One such issue is financial exclusion, as consumer groups and NGOs working on behalf of minority groups require a baseline knowledge of current research trends to take part in societal conversations (Grohmann et al., 2018). The United Nations’ Sustainable Development Goals (SDGs) highlight the importance of financial inclusion for economic growth (Ozili, 2018), with financial literacy and knowledge significantly improving society’s credit access (Kara et al., 2021). The power of knowledge remains with those commercial entities with access to large sums of research funding, hindering social progress in regulatory spaces and also in the protection of disadvantaged members of society. Again, likening the current situation of research data accessibility in financial services research to Foucault’s (2020) power-knowledge theory, the commercial industry, as holders of sensitive personal data on consumers, also holds power. These valuable data are often siloed by commercial entities who have gathered data from their customers. Without a standardised anonymisation framework to allow the transfer of these data for academic analysis, policymakers do not see the full picture relating to the potential for AI applications in financial services. Without the knowledge of the full potential of such applications, there may be regulatory gaps related to AI applications in financial services.
4.2. The Transposability of FAIR Principles to Financial Services Research and FAAIR Adaptation
Following the above analysis, which finds a significant lack of reproducible research on AI applications across finance, tax, and insurance, one must consider the validity of the FAIR Principles in financial services research. Although a step in the right direction for research data transparency and openness, the FAIR Principles as they currently stand do not encapsulate the true meaning of the acronym in English, i.e., the advancement of fair, equitable and inclusive data and research (Sterner & Elliott, 2023). Even if datasets satisfy the FAIR Principles, they could perpetuate existing social injustices borne from sampling biases or inadequate representation of vulnerable groups (Leonelli et al., 2021). Legally, the opacity of black-box AI systems hinders regulatory bodies from determining whether data are processed fairly (Carabantes, 2020). However, evolving XAI methods are enhancing the potential for AI systems’ regulation under the European GDPR (EU, 2016), with Hagras (2018) suggesting how FAIR Data can facilitate an easier move to more explainable AI methods. As financial services data are comprised of customers’ sensitive and personal information, the anonymity of the data subject is paramount. The GDPR protects the data subject’s right to anonymity during data processing stages and ensures that sensitive information is not shared with third parties with whom the data subject has not given consent to view such sensitive personal information (EU, 2016). The FAIR Principles assess the availability of published research data. Considering that financial service research predominantly uses anonymised sensitive information, of which the researcher is usually not the owner, the publication of datasets is not always possible. Therefore, the FAIR Principles are rarely fully satisfied by financial services research. This paper proposes an enhancement of the FAIR Principles to encapsulate the special case of the financial services industry, similar to the extension of the FAIR Principles for medical research proposed by Holub et al. (2018) and Landi et al. (2020) and the CARE Principles[6] which address the importance of Indigenous peoples in making decisions about themselves, their land and waters (Mushi et al., 2020).

Through including an additional facet, “Anonymisation”, the FAAIR Principles (Findable, Accessible, Anonymised, Interoperable, Reusable) will allow for financial services research to be fully accessible and usable to those research and civil society bodies who need data to enact sustainable change in society. Anonymised data encompasses GDPR-compliant data that are not easily traceable back to the original by reducing the precision of data attribute values (with a view to removing them entirely) (El Emam et al., 2015). Though attribute disclosure cannot be entirely avoided (Sun et al., 2011), a set of techniques to minimise risks of privacy breaches is at the heart of Anonymised data in the proposed FAAIR Principles. The ensuing ability of IDOs, NGOs, and civil society to access financial research data will facilitate open science initiatives and citizen empowerment in the face of social inequalities, namely financial exclusion (Janssen et al., 2012; Zhu et al., 2019).
Commercial practices will also benefit from the practice of FAAIR research findings through the adaptation of academic research for commercial use. An example of such AI-driven commercial innovations could include the adoption of novel insurance products proposed by the academic community and their translation into successful insurance product offerings. The Pay-As-You-Move (PAYM) multi-modal insurance product framework proposed by Owens et al. (2024) provides an extension and enhancement of the successful Pay-As-You-Drive (PAYD) insurance product, harnessing AI-driven analytics and smart city technologies in its development. Financial services product innovations are produced and driven by both academia and industry, and the sharing of data and insights between both groups allows for continued successful innovations. Through providing a FAAIR framework for financial services research, open science can become a reality by promoting transparency and inclusivity in financial services product development, policymaking, and decision-making (Beck et al., 2020).
5. Conclusion
Research transparency and reproducibility are key concerns of many researchers and journal publication houses, with analysed datasets often requested upon acceptance of an article for publication. Although this practice is a great effort in providing the academic research community with the means to validate and reuse data for future research projects, it is not always possible in financial services research. An analysis of the applications of AI in the financial services literature set showcases a lack of available data used during research analysis. Often, the FAIR Principles framework is used to assess the level of transparency and accessibility of research projects. However, we argue that such Principles are not altogether applicable to the financial services research domain. Often sensitive and personal data are collected, collated and owned by commercial entities who, for regulatory reasons, cannot provide researchers with such sensitive personal data in the majority of circumstances. By incorporating an additional facet (Anonymised data) in the FAIR Principles, these groups can reduce social injustices and support financial inclusion. The financial services industry is a high-value socio-economic example of where the benefits of FAIR can be increased through the implementation of informed strategies to support it. The FAAIR Principles will enhance the development of explainable and responsible AI to reduce social injustices, in particular financial exclusion.
An open-source solution could provide benefits to research reproducibility. However, the difficulty remains that any strategy requires a dynamic and sustainable solution. In this way, FAAIR is an example of such progressive adaptation. If anonymised, datasets gathered by commercial entities and researchers may be accessed by (other) researchers, encouraging further analysis by the wider academic community. IDOs and NGOs representing the public (including minority groups) in the financial services domain will also enjoy adequate access to research data to support informed decision-making, a need which will be satisfied by data published under the FAAIR Data framework. The value of the FAAIR framework to financial services research lies in the potential to analyse datasets containing sensitive personal data which may have been previously protected under GDPR rules. FAAIR allows for continued adherence to data privacy regulations while also aiding advancements in financial services research. Additionally, researchers are encouraged to practice transparent publication practices by publishing datasets (where possible, considering regulation requirements) alongside their peer-reviewed work. This practice of ensuring studies are reproducible and verifiable will further boost research in AI-applied financial services research.
Consulted and first published under FORCE11 in 2016.
Adapted from Owens et al. (2022).
Throughout this review “articles” refers to both academic articles and conference papers.
Including, yet not exclusive to, the following reviewed articles: Baudry and Robert (2019), Gan (2013), Gan and Huang (2017), and Kowshalya and Nandhini (2018).
Note that Jensen et al. (2023) did not evaluate their data sample using the FAIR Data Principles guidelines but rather a unique Bayesian model of factor replication.
CARE principles = Collective, Authority, Responsibility, Ethics.